来源:蝴蝶之梦天使
链接:http://www.jianshu.com/p/d333cf6ae4b0
在iOS开发中经常需要使用的或不常用的知识点的总结,几年的收藏和积累(踩过的坑)。
一、 iPhone Size
| 手机型号 |
屏幕尺寸 |
| iPhone 4 4s |
320 * 480 |
| iPhone 5 5s |
320 * 568 |
| iPhone 6 6s |
375 * 667 |
| iphone 6 plus 6s plus |
414 * 736 |
二、 给navigation Bar 设置 title 颜色
UIColor *whiteColor = [UIColor whiteColor];
NSDictionary *dic = [NSDictionary dictionaryWithObject:whiteColor forKey:NSForegroundColorAttributeName];
[self.navigationController.navigationBar setTitleTextAttributes:dic];
三、 如何把一个CGPoint存入数组里
CGPoint itemSprite1position = CGPointMake(100, 200);
NSMutableArray * array = [[NSMutableArray alloc] initWithObjects:NSStringFromCGPoint(itemSprite1position),nil];
// 从数组中取值的过程是这样的:
CGPoint point = CGPointFromString([array objectAtIndex:0]);
NSLog(@“point is %@.”, NSStringFromCGPoint(point));
谢谢@bigParis的建议,可以用NSValue进行基础数据的保存,用这个方法更加清晰明确。
CGPoint itemSprite1position = CGPointMake(100, 200);
NSValue *originValue = [NSValue valueWithCGPoint:itemSprite1position];
NSMutableArray * array = [[NSMutableArray alloc] initWithObjects:originValue, nil];
// 从数组中取值的过程是这样的:
NSValue *currentValue = [array objectAtIndex:0];
CGPoint point = [currentValue CGPointValue];
NSLog(@“point is %@.”, NSStringFromCGPoint(point));
现在Xcode7后OC支持泛型了,可以用NSMutableArray *array来保存。
四、 UIColor 获取 RGB 值
UIColor *color = [UIColor colorWithRed:0.0 green:0.0 blue:1.0 alpha:1.0];
const CGFloat *components = CGColorGetComponents(color.CGColor);
NSLog(@“Red: %f”, components[0]);
NSLog(@“Green: %f”, components[1]);
NSLog(@“Blue: %f”, components[2]);
NSLog(@“Alpha: %f”, components[3]);
五、 修改textField的placeholder的字体颜色、大小
self.textField.placeholder = @“username is in here!”;
[self.textField setValue:[UIColor redColor] forKeyPath:@“_placeholderLabel.textColor”];
[self.textField setValue:[UIFont boldSystemFontOfSize:16] forKeyPath:@“_placeholderLabel.font”];
六、两点之间的距离
static __inline__ CGFloat CGPointDistanceBetweenTwoPoints(CGPoint point1, CGPoint point2) { CGFloat dx = point2.x – point1.x; CGFloat dy = point2.y – point1.y; return sqrt(dx*dx + dy*dy);}
七、IOS开发-关闭/收起键盘方法总结
1、点击Return按扭时收起键盘
– (BOOL)textFieldShouldReturn:(UITextField *)textField
{
return [textField resignFirstResponder];
}
2、点击背景View收起键盘(你的View必须是继承于UIControl)
[self.view endEditing:YES];
3、你可以在任何地方加上这句话,可以用来统一收起键盘
[[[UIApplication sharedApplication] keyWindow] endEditing:YES];
八、在使用 ImagesQA.xcassets 时需要注意
将图片直接拖入image到ImagesQA.xcassets中时,图片的名字会保留。
这个时候如果图片的名字过长,那么这个名字会存入到ImagesQA.xcassets中,名字过长会引起SourceTree判断异常。
九、UIPickerView 判断开始选择到选择结束
开始选择的,需要在继承UiPickerView,创建一个子类,在子类中重载
– (UIView*)hitTest:(CGPoint)point withEvent:(UIEvent*)event
当[super hitTest:point withEvent:event]返回不是nil的时候,说明是点击中UIPickerView中了。
结束选择的, 实现UIPickerView的delegate方法
– (void)pickerView:(UIPickerView*)pickerView didSelectRow:(NSInteger)row inComponent:(NSInteger)component
当调用这个方法的时候,说明选择已经结束了。
十、iOS模拟器 键盘事件
当iOS模拟器 选择了Keybaord->Connect Hardware keyboard 后,不弹出键盘。
当代码中添加了
[[NSNotificationCenter defaultCenter] addObserver:self
selector:@selector(keyboardWillHide)
name:UIKeyboardWillHideNotification
object:nil];
进行键盘事件的获取。那么在此情景下将不会调用- (void)keyboardWillHide.
因为没有键盘的隐藏和显示。
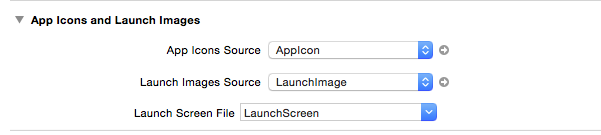
十一、在ios7上使用size classes后上面下面黑色
使用了size classes后,在ios7的模拟器上出现了上面和下面部分的黑色
可以在General->App Icons and Launch Images->Launch Images Source中设置Images.xcassets来解决。
十二、设置不同size在size classes
Font中设置不同的size classes。

十三、线程中更新 UILabel的text
[self.label1 performSelectorOnMainThread:@selector(setText:) withObject:textDisplay
waitUntilDone:YES];
abel1 为UILabel,当在子线程中,需要进行text的更新的时候,可以使用这个方法来更新。
其他的UIView 也都是一样的。
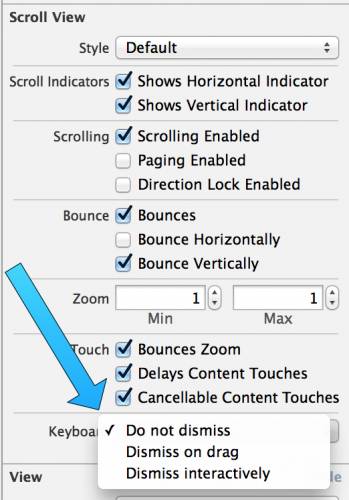
十四、使用UIScrollViewKeyboardDismissMode实现了Message app的行为
像Messages app一样在滚动的时候可以让键盘消失是一种非常好的体验。然而,将这种行为整合到你的app很难。幸运的是,苹果给UIScrollView添加了一个很好用的属性keyboardDismissMode,这样可以方便很多。
现在仅仅只需要在Storyboard中改变一个简单的属性,或者增加一行代码,你的app可以和办到和Messages app一样的事情了。
这个属性使用了新的UIScrollViewKeyboardDismissMode enum枚举类型。这个enum枚举类型可能的值如下:
typedef NS_ENUM(NSInteger, UIScrollViewKeyboardDismissMode) {
UIScrollViewKeyboardDismissModeNone,
UIScrollViewKeyboardDismissModeOnDrag, // dismisses the keyboard when a drag begins
UIScrollViewKeyboardDismissModeInteractive, // the keyboard follows the dragging touch off screen, and may be pulled upward again to cancel the dismiss
} NS_ENUM_AVAILABLE_IOS(7_0);
以下是让键盘可以在滚动的时候消失需要设置的属性:
十五、报错 “_sqlite3_bind_blob”, referenced from:
将 sqlite3.dylib加载到framework
十六、ios7 statusbar 文字颜色
iOS7上,默认status bar字体颜色是黑色的,要修改为白色的需要在infoPlist里设置UIViewControllerBasedStatusBarAppearance为NO,然后在代码里添加:
[application setStatusBarStyle:UIStatusBarStyleLightContent];
十七、获得当前硬盘空间
NSFileManager *fm = [NSFileManager defaultManager];
NSDictionary *fattributes = [fm attributesOfFileSystemForPath:NSHomeDirectory() error:nil];
NSLog(@“容量%lldG”,[[fattributes objectForKey:NSFileSystemSize] longLongValue]/1000000000);
NSLog(@“可用%lldG”,[[fattributes objectForKey:NSFileSystemFreeSize] longLongValue]/1000000000);
十八、给UIView 设置透明度,不影响其他sub views
UIView设置了alpha值,但其中的内容也跟着变透明。有没有解决办法?
设置background color的颜色中的透明度
比如:
[self.testView setBackgroundColor:[UIColor colorWithRed:0.0 green:1.0 blue:1.0 alpha:0.5]];
设置了color的alpha, 就可以实现背景色有透明度,当其他sub views不受影响给color 添加 alpha,或修改alpha的值。
// Returns a color in the same color space as the receiver with the specified alpha component.
– (UIColor *)colorWithAlphaComponent:(CGFloat)alpha;
// eg.
[view.backgroundColor colorWithAlphaComponent:0.5];
十九、将color转为UIImage
//将color转为UIImage
– (UIImage *)createImageWithColor:(UIColor *)color
{
CGRect rect = CGRectMake(0.0f, 0.0f, 1.0f, 1.0f);
UIGraphicsBeginImageContext(rect.size);
CGContextRef context = UIGraphicsGetCurrentContext();
CGContextSetFillColorWithColor(context, [color CGColor]);
CGContextFillRect(context, rect);
UIImage *theImage = UIGraphicsGetImageFromCurrentImageContext();
UIGraphicsEndImageContext();
return theImage;
}
二十、NSTimer 用法
NSTimer *timer = [NSTimer scheduledTimerWithTimeInterval:.02 target:self selector:@selector(tick:) userInfo:nil repeats:YES];
[[NSRunLoop currentRunLoop] addTimer:timer forMode:NSRunLoopCommonModes];
在NSRunLoop 中添加定时器.
二十一、Bundle identifier 应用标示符
Bundle identifier 是应用的标示符,表明应用和其他APP的区别。
二十二、NSDate 获取几年前的时间
eg. 获取到40年前的日期
NSCalendar *gregorian = [[NSCalendar alloc] initWithCalendarIdentifier:NSGregorianCalendar];
NSDateComponents *dateComponents = [[NSDateComponents alloc] init];
[dateComponents setYear:-40];
self.birthDate = [gregorian dateByAddingComponents:dateComponents toDate:[NSDate date] options:0];
二十三、iOS加载启动图的时候隐藏statusbar
只需需要在info.plist中加入Status bar is initially hidden 设置为YES就好

二十四、iOS 开发,工程中混合使用 ARC 和非ARC
Xcode 项目中我们可以使用 ARC 和非 ARC 的混合模式。
如果你的项目使用的非 ARC 模式,则为 ARC 模式的代码文件加入 -fobjc-arc 标签。
如果你的项目使用的是 ARC 模式,则为非 ARC 模式的代码文件加入 -fno-objc-arc 标签。
添加标签的方法:
- 打开:你的target -> Build Phases -> Compile Sources.
- 双击对应的 *.m 文件
- 在弹出窗口中输入上面提到的标签 -fobjc-arc / -fno-objc-arc
- 点击 done 保存
二十五、iOS7 中 boundingRectWithSize:options:attributes:context:计算文本尺寸的使用
之前使用了NSString类的sizeWithFont:constrainedToSize:lineBreakMode:方法,但是该方法已经被iOS7 Deprecated了,而iOS7新出了一个boudingRectWithSize:options:attributes:context方法来代替。
而具体怎么使用呢,尤其那个attribute
NSDictionary *attribute = @{NSFontAttributeName: [UIFont systemFontOfSize:13]};
CGSize size = [@“相关NSString” boundingRectWithSize:CGSizeMake(100, 0) options: NSStringDrawingTruncatesLastVisibleLine | NSStringDrawingUsesLineFragmentOrigin | NSStringDrawingUsesFontLeading attributes:attribute context:nil].size;
二十六、NSDate使用 注意
NSDate 在保存数据,传输数据中,一般最好使用UTC时间。
在显示到界面给用户看的时候,需要转换为本地时间。
二十七、在UIViewController中property的一个UIViewController的Present问题
如果在一个UIViewController A中有一个property属性为UIViewController B,实例化后,将BVC.view 添加到主UIViewController A.view上,如果在viewB上进行 – (void)presentViewController:(UIViewController *)viewControllerToPresent animated: (BOOL)flag completion:(void (^)(void))completion NS_AVAILABLE_IOS(5_0);的操作将会出现,“ Presenting view controllers on detached view controllers is discouraged ” 的问题。
以为BVC已经present到AVC中了,所以再一次进行会出现错误。
可以使用
[self.view.window.rootViewController presentViewController:imagePicker
animated:YES
completion:^{
NSLog(@“Finished”);
}];
来解决。
二十八、UITableViewCell indentationLevel 使用
UITableViewCell 属性 NSInteger indentationLevel 的使用, 对cell设置 indentationLevel的值,可以将cell 分级别。
还有 CGFloat indentationWidth; 属性,设置缩进的宽度。
总缩进的宽度: indentationLevel * indentationWidth
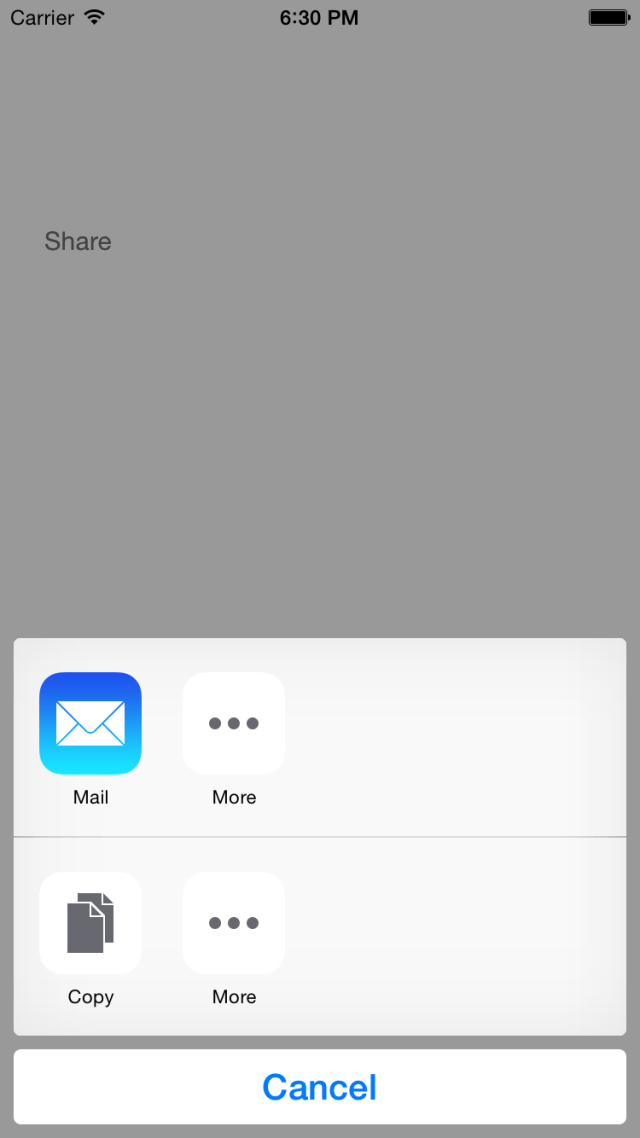
二十九、ActivityViewController 使用AirDrop分享
使用AirDrop 进行分享:
NSArray *array = @[@“test1”, @“test2”];
UIActivityViewController *activityVC = [[UIActivityViewController alloc] initWithActivityItems:array applicationActivities:nil];
[self presentViewController:activityVC animated:YES
completion:^{
NSLog(@“Air”);
}];
就可以弹出界面:
三十、获取CGRect的height
获取CGRect的height, 除了 self.createNewMessageTableView.frame.size.height 这样进行点语法获取。
还可以使用CGRectGetHeight(self.createNewMessageTableView.frame) 进行直接获取。
除了这个方法还有 func CGRectGetWidth(rect: CGRect) -> CGFloat
等等简单地方法
func CGRectGetMinX(rect: CGRect) -> CGFloat
func CGRectGetMidX(rect: CGRect) -> CGFloat
func CGRectGetMaxX(rect: CGRect) -> CGFloat
func CGRectGetMinY(rect: CGRect) -> CGFloat
三十一、打印 %
NSString *printPercentStr = [NSString stringWithFormat:@“%%”];
三十二、在工程中查看是否使用 IDFA
allentekiMac-mini:JiKaTongGit lihuaxie$ grep -r advertisingIdentifier .
grep: ./ios/Framework/AMapSearchKit.framework/Resources: No such file or directory
Binary file ./ios/Framework/MAMapKit.framework/MAMapKit matches
Binary file ./ios/Framework/MAMapKit.framework/Versions/2.4.1.e00ba6a/MAMapKit matches
Binary file ./ios/Framework/MAMapKit.framework/Versions/Current/MAMapKit matches
Binary file ./ios/JiKaTong.xcodeproj/project.xcworkspace/xcuserdata/lihuaxie.xcuserdatad/UserInterfaceState.xcuserstate matches
allentekiMac-mini:JiKaTongGit lihuaxie$
打开终端,到工程目录中, 输入:
grep -r advertisingIdentifier .
可以看到那些文件中用到了IDFA,如果用到了就会被显示出来。
三十三、APP 屏蔽 触发事件
// Disable user interaction when download finishes
[[UIApplication sharedApplication] beginIgnoringInteractionEvents];
三十四、设置Status bar颜色
status bar的颜色设置:
如果没有navigation bar, 直接设置 // make status bar background color
self.view.backgroundColor = COLOR_APP_MAIN;
如果有navigation bar, 在navigation bar 添加一个view来设置颜色。// status bar color
UIView *view = [[UIView alloc] initWithFrame:CGRectMake(0, -20, ScreenWidth, 20)];
[view setBackgroundColor:COLOR_APP_MAIN];
[viewController.navigationController.navigationBar addSubview:view];
三十五、NSDictionary 转 NSString
// Start
NSDictionary *parametersDic = [NSDictionary dictionaryWithObjectsAndKeys:
self.providerStr, KEY_LOGIN_PROVIDER,
token, KEY_TOKEN,
response, KEY_RESPONSE,
nil];
NSData jsonData = parametersDic == nil ? nil : [NSJSONSerialization dataWithJSONObject:parametersDic options:0 error:nil];
NSString requestBody = [[NSString alloc] initWithData:jsonData encoding:NSUTF8StringEncoding];
将dictionary 转化为 NSData, data 转化为 string .
三十六、iOS7 中UIButton setImage 没有起作用
如果在iOS7 中进行设置image 没有生效。
那么说明UIButton的 enable 属性没有生效是NO的。 **需要设置enable 为YES。**
三十七、User-Agent 判断设备
UIWebView 会根据User-Agent 的值来判断需要显示哪个界面。
如果需要设置为全局,那么直接在应用启动的时候加载。
(void)appendUserAgent
{
NSString oldAgent = [self.WebView stringByEvaluatingJavaScriptFromString:@”navigator.userAgent”];
NSString newAgent = [oldAgent stringByAppendingString:@”iOS”];
NSDictionary *dic = [[NSDictionary alloc] initWithObjectsAndKeys:
newAgent, @”UserAgent”, nil];
1
newAgent, @”UserAgent”, nil];
[[NSUserDefaults standardUserDefaults] registerDefaults:dic];
}
@“iOS” 为添加的自定义。
三十八、UIPasteboard 屏蔽paste 选项
当UIpasteboard的string 设置为@“” 时,那么string会成为nil。 就不会出现paste的选项。
三十九、class_addMethod 使用
当 ARC 环境下
class_addMethod([self class], @selector(resolveThisMethodDynamically), (IMP) myMethodIMP, “v@:”);
使用的时候@selector 需要使用super的class,不然会报错。
当MRC环境下
class_addMethod([EmptyClass class], @selector(sayHello2), (IMP)sayHello, “v@:”);
可以任意定义。但是系统会出现警告,忽略警告就可以。

























{kind=link}
{kind=link}